始于
分类:Notes
Tags: [ Notes ]
CNN卷积神经网络
CNN Notes
CNN卷积神经网络
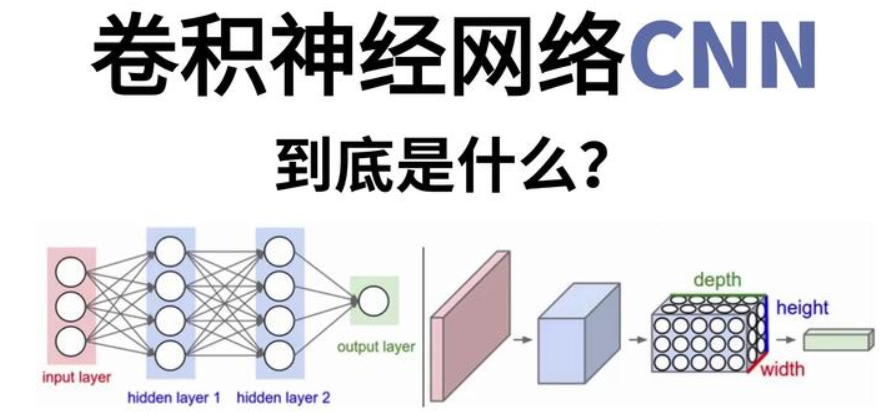
传统神经网络和CNN卷积神经网络的区别:
传统神经网络是一维的,只有向量。
CNN卷积神经网络是三维的。height、width、depth
我的理解:
把一堆木浆倒入水池(输入层),再用棍子搅动(卷积层),然后慢慢沉淀(池化层),排出水后,把沉淀物挤压成型(全连接层)
卷积
卷积的含义就是特征提取。
卷积做的事情就是把图片划分成多个小区域,计算每一块的特征值。
图像的颜色通道RGB,32x32x3
计算特征值的时候是每个通道分离开,分别计算特征值,然后再融合melt在一块,相加1+2+3=6。
总的是7x7x3,分成RGB,每个分别为7x7x1
卷积核大小决定了从多大的区域内计算出来一个特征值。
通过filter隐藏参数得到一个值。
特征值计算方法,用merge。
卷积核内数值怎么设置的?
一个通道,对应位置相乘再求和,做了一次内积。
再把RGB三个通道数值加起来,得到最终的一张特征图。
设置不同的卷积核得到不同的特征图。得到丰富的特征。
注意:
计算同一层的特征图的时候,卷积核可以选择不同的值,但是维度必须相同,比如R层用的都是3x3的。
不同层直接卷积核可以选择不同的,比如R层用3x3,G层用4x4。
output volume中3x3x2的2表示的含义是由两张特征图叠加而来的。
卷积不是只做一次,但是不是对同一张图做卷积,而是对上一次卷积得到的特征图进行卷积。就像拼图。不断弱化非特征部分的特征值,突出边缘轮廓。
涉及到的参数:
步长:
步长小细密度的提取特征,详细但是效率低。
步长大粗密度提取。
卷积核尺寸
卷积核尺寸3x3常见,越小细密度,越大粗密度
边缘填充
边缘填充——图像灰色部分全填充了0
为了解决,在卷积核移动过程中有些点比如边界上的点天生被计算的次数少,所以在边缘填充了一圈0,让边缘的点不那么边缘,提高利用和计算的次数,弥补信息确实的问题(+pad 1)。填0不会产生其他的影响。
两个文本,一个100词,另一个120词,需要把100词的文本用0填充到120词。也是边缘填充的思想。
卷积核个数:
卷积核个数决定最终算的过程中要得到多少个特征图,n个卷积核得到n个特征图。
自己的理解:
output特征图维度 = (input图像维度 - 卷积核维度 + 边缘填充层数*2)/卷积核步长 + 1
如下图:3 = (5 - 3+1*2)/2 + 1
输入,填充,核大小,步长
卷积参数共享
条件:假设原图为32x32x3,卷积核为5x5x3,步长为1,边缘填充2圈
CNN:其实就是RGB中每一层一张图中用同一个卷积核。这样比传统神经网络需要的权重参数少很多,传统的神经网络每一个区域用的是不同的卷积核,如左边的图
5x5x3x10+10=760
5x5的卷积核,3层,10个卷积核,10参数b
传统的:原本是每移动一次换一个卷积核,需要的参数个数:
(32-5+2x2)/1+1=32(特征图尺寸)
3x32x32x5x5=51200
3层RGB,32x32的特征图尺寸,5x5的卷积核
池化层:
压缩作用,下采样。pool
提取出来很多特征但是不是所有的特征都是有用的。剔除部分不重要的,选择重要的。
224x224x64->112x112x64
特定值数量缩减了四分之一。
只能缩减,不能修改特征图的个数
最大池化:没有任何计算只是进行筛选,提取出最大值。1,1,5,6->6
平均池化:把每块区域的特征值求平均。1,1,5,6->3(缺点:用的很少,丢失了最大特征值)
判断卷积神经网络层数:
带参数的才能算作一层。
conv卷积层带参数,relu激活层不带参数,池化层也没有参数,FC也需要参数。所以下图的卷积神经网络,有6+1=7层,6层卷积层,1层FC
每一个relu激活层都有一个conv卷积层,成为一个组合。
两次卷积一次池化,提取、压缩,提取、压缩。
怎么把特征值做成5分类的?(car、track、airplane、ship、horse)
通过FC,
FC[,5]
代表前面提取出来的特征,但是不能连接三维的,32x32x10,需要把这个特征图拉成一个特征向量连接,到全连接层
5代表5分类
因为是4维的,所以需要加上一个参数b,batch,为10
感受野:
后面的特征值能回溯到是由什么计算来的。感受到原始数据的大小。回溯到原始尺寸。
数据增强:
图像数据不够:将图像进行镜像翻转一张变成两张。数据量很重要,用大量的数据往里面堆。
图片角度旋转
放大缩小
放大缩小同时镜像翻转
关键是:使得图像像素点,特征点矩阵改变了就好。
重新调整图片输入大小,像素,因为VGG和Resnet等神经网络要求输入图片大小要24x24的,但是提供的图片是不规则的可能是1024x1024,或者256x256的
torchvision中的三大核心模块transform、datasets、models
transform模块用于数据预处理
网络解读
P14,重新看,讲解一个简单的神经网络代码
nn.Linear(32*7*7,10)
(w,b)两个维度,b是最后几分类,如果是分成10类,比如有10种车辆类型。w是全连接层权重参数的个数,
计算[w,b]中w的值
输入大小(1,28,28)1代表1RGB中的一层,28代表图原始尺寸
out_channels = 16,kernel_size = 5卷积核大小为5,stride = 1步长为1,padding = 2边缘填充2圈
计算(28-5+2*2)/1+1 = 28
卷积层1
conv1(16,28,28)
16代表有16个不同的卷积核,输出16个特征图,28代表第一次卷积得到特征图的尺寸
最大池化层1
relu(14,14,16)
nn.MaxPool1d(kernel_size = 2)
代表每个维度缩减一半
卷积层2
Conv2d(16,32,5,1,2)#分别表示in_channels = 16,out_channels = 32,kernel_size = 5卷积核大小为5,stride = 1步长为1,padding = 2边缘填充2圈
conv2(14,14,32)
计算(14-5+2*2)/1+1 = 14
最大池化层2
nn.MaxPool2d(2)#省略了kernel_size = 2,直接写2
relu(7,7,32)
全连接层
7x7x32
[w,b]->[1568,10]
经典网络-Alexnet
神经网络只有8层
11x11 filters卷积核尺寸,目前最多的是3x3的
stride 4 步长为4
pad 0,边缘填充0圈
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2)
self.conv2 = nn.Conv2d(64, 192, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(192, 384, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(384, 256, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.fc1 = nn.Linear(256 * 6 * 6, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 1000) # 1000 classes for ImageNet
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, kernel_size=3, stride=2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, kernel_size=3, stride=2)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = F.max_pool2d(x, kernel_size=3, stride=2)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
经典网络-VGG
所有卷积核大小都是3x3的,都是细密度提取的
神经网络有16、19层
使用maxpool,每次池化后损失了特征信息,怎么弥补回来呢?每次卷积之前使得上一次的特征图翻倍乘2,再进行下一次卷积。
层数越多效果越好吗?
发现16层时比30层效果好,不一定每一次卷积效果都好,如果出现了效果差的一次,把差的特征继续卷积,效果反而不如意。
class VGG(nn.Module):
def __init__(self, features, num_classes=1000):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
经典网络-Resnet,残差:
从20层加到56层,其中肯定有训练的不好的一层,导致把成绩拉下来了。
怎么把好的特征堆叠起来,但是不能受差的影响到作用。
怎么识别出卷积的不好的一层?
提出了,同等映射的方法。卷积层加进来就不能删除了,识别出不好的卷积之后给它的权重参数(就是提取出来的特征图中的特征值)设置成0,加进来但是不使用它。
具体实现:20层后的某一次,再进行两次卷积,原封不动的拿过来,做一个加法,堆叠。
会出现很多次白白跑,但是至少有所提升,不会比原来的效果差。
做科研,竞赛首选Resnet网络,深层网络
Resnet当作特征提取,不建议当作分类网络,因为一个问题是分类还是回归决定了损失函数和最后层(全连接层)是怎么连的。可以用到各种物体检测,物体追踪,分类,检索,识别,什么任务都能用,通用的神经网络。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
较为复杂的图片识别神经网络——鸢尾花集:
torchvision需要自己另外安装,里面含有很多提前写好的代码块比如,resnet模型,VGG模型,Alexnet模型。
torchvision中的三大核心模块transform、datasets、models
#通过此命令安装
pip install torchvision
#就可以使用torchvision中的三大核心模块了
比如:用torchvision中的datasets,直接复制代码块就好。写好了API,直接调用就好。
Datasets — Torchvision 0.16 documentation (pytorch.org)