作者
Cendok
始于
分类:MRS
Tags: [ MRS ]
BaseLine模板匹配
始于
分类:MRS
Tags: [ MRS ]
BaseLine模板匹配
MRS模板匹配
Baseline模板匹配
从音频信号中识别出主音系统、主音音高、模式模式和模式类型,自动标注乐曲到对应的五音调式。
librosa库提取色度特征,求和得到十二位色度向量Tensor,不含八度信息。
构建tonggong System模板,循环移动得到其余模板。
System
对于System,提取未知音频的十二位色度向量,与已有的十二给模板比较,计算皮尔森相关系数,系数最大的即匹配程度最高的,就是该乐曲的System。
Tonic
对于Tonic,librosa库提取主音音高特征,十二位色度向量,把最后500帧的色度特征相加就是音高名称。
Pattern
对于Pattern,根据以下推断方法得到。
Pattern推断方法:
t(Tonic),s(System)
当t = s时,为Gong模式。当t比s高2个半音时,它是尚模式。高4个半音为觉式,高7个半音为直式,高9个半音为余式。
Type
Type,模板由0和1构成,识别方法类似System。
实现音频分析的基本步骤,使用librosa包来处理音频数据:
- 获取色度特征:使用librosa包获取整个音频的色度特征。色度特征是一个十二维向量,表示音频中各个音高的能量分布,不考虑八度信息。
- 求和色度向量:将获取到的色度特征向量求和,得到一个十二维的色度向量,该向量反映了整个音频中每个音高的总能量。
- TongGong体系分类:首先定义C TongGong体系的模板(1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0),其他TongGong体系的模板可以通过循环移动该模板获得。
- 计算皮尔森相关系数:分别计算色度向量与每个TongGong体系模板之间的皮尔森相关系数,以评估它们之间的匹配程度。
- 识别TongGong体系:选取具有最大皮尔森相关系数的模板,该模板对应的TongGong体系即为识别结果。
- 识别主音音高:分析音频的最后500帧的色度特征,按音高求和,最大值对应的音高即视为主音音高。
- 调式类型识别:根据每种调式对应的音阶,构造由0和1组成的模板。使用与TongGong体系识别类似的方法计算每个模板与色度向量之间的匹配度,以识别调式类型。
- 得出调式的模式:结合TongGong体系和主音音高的识别结果,最终确定音频的调式模式。
输入
一维音频转换成二维的频谱图,可以传入整个频谱图训练,也可以切割之后传入训练,在组合训练结果。
结果评估
开发了7个精度度量来评估识别结果
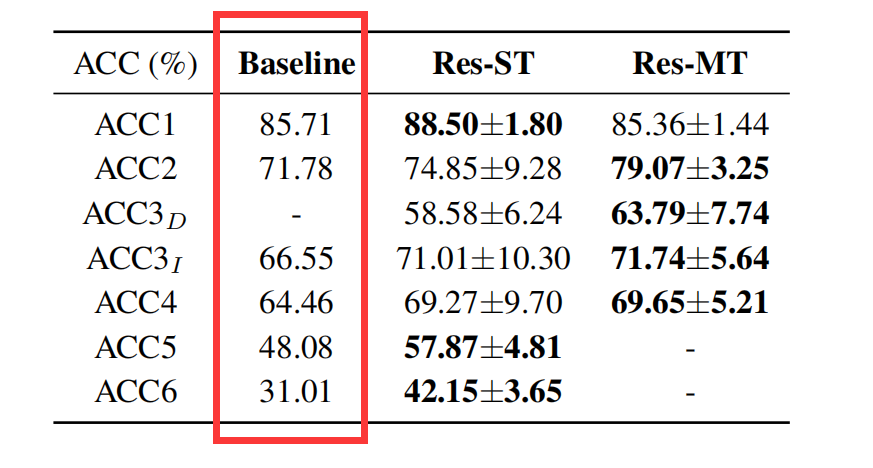
ACC1为System的精确值、ACC2为Tonic的精确值、ACC3为Pattern的精确值、ACC4为Tonic和Pattern的精确值的均值、ACC5为Type的精确值、ACC6为Tonic、Pattern和Type精确值的均值
实现
# -*- coding: gb2312 -*-
import os
import librosa
import numpy as np
import pandas as pd
from scipy.stats import pearsonr
def analyze_audio(file_path):
y, sr = librosa.load(file_path)
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
chroma_sum = np.sum(chroma, axis=1)
# System/Tonic模板
pitch_names = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
c_tonggong = np.array([1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0]) # C TongGong体系System的模板
templates = [np.roll(c_tonggong, i) for i in range(12)] # System循环生成其他十二个模板TongGong体系的模板,即从C到B按顺序
correlations = [pearsonr(chroma_sum, template)[0] for template in templates]
tonggong_index = pitch_names[np.argmax(correlations)]# 同宫系统映射关系,映射到标签,enumerate(pitch_names) 会生成 (0, 'C'), (1, 'D'), (2, 'E')
tonggong_system_mapping = {name: i for i, name in enumerate(pitch_names)}# 映射到数字
System_number = tonggong_system_mapping[tonggong_index]
#tonic映射到数字,主音提取后500帧的色度特征
tonic_index = np.argmax(np.sum(chroma[:, -500:], axis=1))
tonic = pitch_names[tonic_index]
tonic_number = tonggong_system_mapping[tonic]# 主音音高/Pitch of Tonic:规则与同宫系统/TongGong System相同,所以直接用tonggong_system_mapping映射到数字
# Type调式模板
mode_templates_Type = {
'Heptatonic Yanyue': np.array([1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0]),
'Heptatonic Qingyue': np.array([1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0]),
'Heptatonic Yayue': np.array([1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0]),
'Hexatonic (Biangong)': np.array([1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0]),
'Hexatonic (Qingjue)': np.array([1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1]),
'Pentatonic': np.array([1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1])
}
type_mapping = {
'Pentatonic': 0,
'Hexatonic (Qingjue)': 1,
'Hexatonic (Biangong)': 2,
'Heptatonic Yayue': 3,
'Heptatonic Qingyue': 4,
'Heptatonic Yanyue': 5
}#Type调式映射关系
mode_correlations = {Type: pearsonr(chroma_sum, template)[0] for Type, template in mode_templates_Type.items()}
identified_Type = max(mode_correlations, key=mode_correlations.get)
identified_Type_number = type_mapping[identified_Type] # 映射到数字
#Pattern计算
"""
调式样式/Type Pattern:
0--宫/Gong
1--商/Shang
2--角/Jue
3--徵/Zhi
4--羽/Yu
"""
half_tone_difference = (tonic_number - System_number) % 12# 计算半音差距
if half_tone_difference == 0:# 根据半音差距判断模式
pattern_number = 0
elif half_tone_difference == 2:
pattern_number = 1
elif half_tone_difference == 4:
pattern_number = 2
elif half_tone_difference == 7:
pattern_number = 3
elif half_tone_difference == 9:
pattern_number = 4
else:
pattern_number = 9 # pattern_number = 9无法确定模式Pattern
return System_number, tonic_number, identified_Type_number,pattern_number
# 文件夹路径
folder_path = r"E:\Code\CNPM_audio"# 文件夹路径
true_labels_df = pd.read_csv(r'E:\Code\label.csv', encoding='utf-8')
correct_System = 0
correct_Tonic = 0
correct_Type = 0
correct_Pattern = 0
total_files = 0
for _, row in true_labels_df.iterrows():
file_name = row['File_Name']
true_tonggong = row['System']
true_tonic = row['Tonic']
true_Type = row['Type']
true_Pattern = row['Pattern']
file_path = os.path.join(folder_path, file_name)
if os.path.exists(file_path):
total_files += 1
tonggong_index, tonic, identified_Type,identified_Pattern = analyze_audio(file_path)
if tonggong_index == true_tonggong:
correct_System += 1
if tonic == true_tonic:
correct_Tonic += 1
if identified_Type == true_Type:
correct_Type += 1
if identified_Pattern == true_Pattern:
correct_Pattern += 1
if total_files > 0:
print(f"ACC1(System accuracy): {correct_System / total_files:.2f}")
print(f"ACC2(Tonic accuracy): {correct_Tonic / total_files:.2f}")
print(f"ACC3I(Pattern accuracy): {correct_Pattern / total_files:.2f}")
print(f"ACC4(Tonic and Pattern Average accuracy): {(correct_Pattern+correct_Tonic) / (2*total_files):.2f}")
print(f"ACC5(Type accuracy): {correct_Type / total_files:.2f}")
print(f"ACC6(Tonic, Pattern and Type Average accuracy): {(correct_Pattern+correct_Tonic+correct_Type) / (3*total_files):.2f}")
else:
print("No files were analyzed.")