作者
Cendok
始于
分类:MRS
Tags: [ MRS ]
多任务残差网络ResNet
始于
分类:MRS
Tags: [ MRS ]
多任务残差网络ResNet
MRS多任务残差网络
ResNet18多任务网络架构
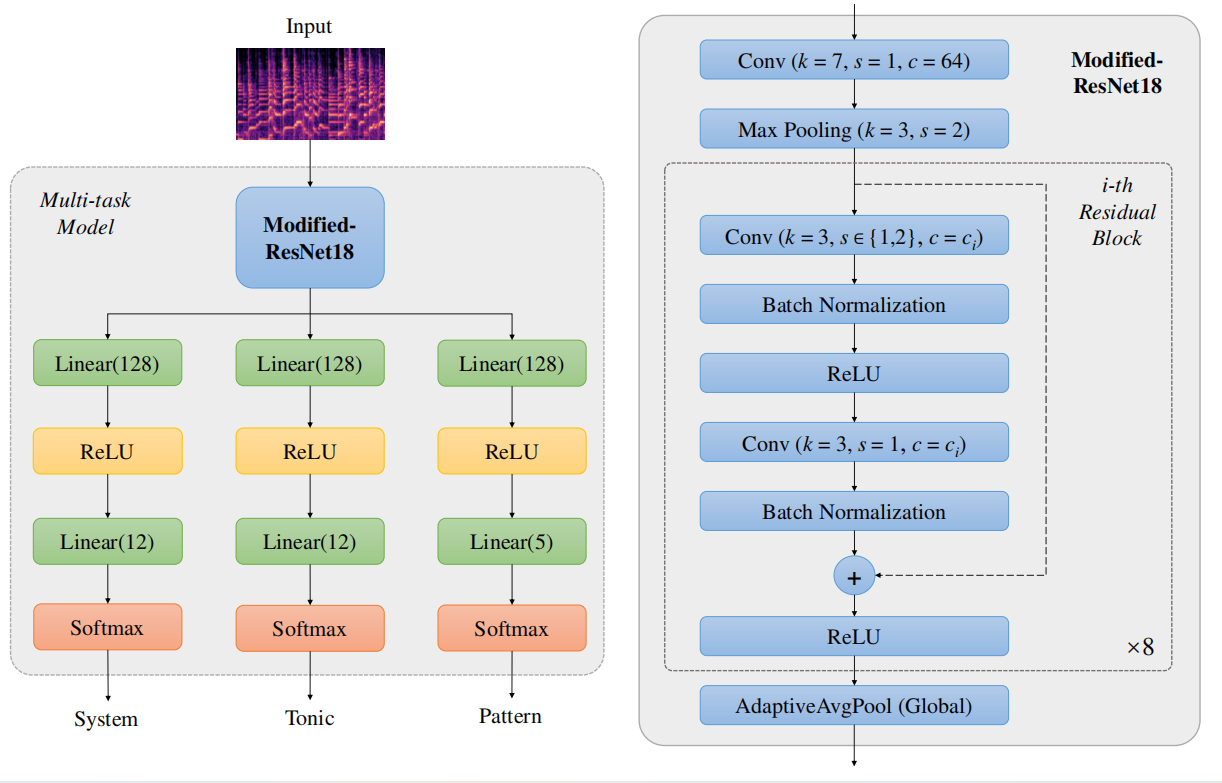
-
输入层:
- 接受输入图像数据,通常是经过一些预处理步骤的图像张量。
-
初始卷积层(Conv):
- 卷积核大小(k): 7x7
- 步长(s): 1
- 输出通道数(c): 64
- 作用:用于提取图像的初步特征。
-
最大池化层(Max Pooling):
- 池化核大小: 3x3
- 步长: 2
- 作用:用于降低特征的空间维度,并提高对输入变化的不变性。
-
残差块(Residual Blocks):
- 由两个大小为 3x3 的卷积层组成,步长(s)为 1 或 2。
- 每个卷积层后面接着批归一化和ReLU激活函数。
- 输出通道数(c): 取决于残差块的设置。
- 重复次数:ResNet18特定的重复次数,一般为 2, 2, 2, 2。
- 残差连接:每个块的输出与输入通过相加操作融合,再通过ReLU激活。
-
全局平均池化层(AdaptiveAvgPool):
- 缩减特征图至 1x1 的尺寸,为连接全连接层做准备。
-
多任务分支:
-
每个任务有独立的全连接层和分类器。
-
分支1:
- 全连接层(Linear): 输入特征数与ResNet18最后一层输出特征数相同,输出特征数为 128。
- 激活函数(ReLU): 非线性激活。
- 第二个全连接层(Linear): 输出特征数为任务1的分类数。(12个分类,’C’, ‘C#’, ‘D’, ‘D#’, ‘E’, ‘F’, ‘F#’, ‘G’, ‘G#’, ‘A’, ‘A#’, ‘B’)
- 分类器(Softmax): 将输出转化为概率分布。
-
分支2:
-
全连接层(Linear): 同上。
-
激活函数(ReLU): 同上。
-
第二个全连接层(Linear): 输出特征数为任务2的分类数。(12个分类,’C’, ‘C#’, ‘D’, ‘D#’, ‘E’, ‘F’, ‘F#’, ‘G’, ‘G#’, ‘A’, ‘A#’, ‘B’)
-
分类器(Softmax): 同上。
分支3:
- 全连接层(Linear): 同上。
- 激活函数(ReLU): 同上。
- 第二个全连接层(Linear): 输出特征数为任务3的分类数。(5个分类,宫商角徵羽)
- 分类器(Softmax): 同上。
-
-
实现
import os
import numpy as np
import pandas as pd
import librosa
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from sklearn.model_selection import train_test_split
from torch.nn.utils.rnn import pad_sequence
def generate_cqt_spectrogram(file_path, resample_rate=5, segment_duration=20):
y, sr = librosa.load(file_path, sr=None)
cqt = librosa.cqt(y, sr=sr, fmin=librosa.note_to_hz('C1'), n_bins=168, bins_per_octave=24)
cqt_amplitude = np.abs(cqt)#标准化
cqt_resampled = librosa.resample(cqt_amplitude, orig_sr=sr, target_sr=resample_rate, axis=1)#下采样
#计算一个片段中的样本数
samples_per_segment = resample_rate * segment_duration#5*20=100个时间点
total_segments = int(np.ceil(cqt_resampled.shape[1] / samples_per_segment))
segments = []
for i in range(total_segments):#如果末尾超过 CQT 的长度,则用零填充剩余部分,达到指定长度
start = i * samples_per_segment
end = start + samples_per_segment
if end > cqt_resampled.shape[1]:
padding_length = end - cqt_resampled.shape[1]
padding = np.zeros((cqt_resampled.shape[0], padding_length))
segment = np.hstack((cqt_resampled[:, start:cqt_resampled.shape[1]], padding))
else:
segment = cqt_resampled[:, start:end]
segments.append(segment)
segments = np.array(segments) # 输出为数组格式
print("segments shape:", segments.shape)
return segments
class AudioDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
audio_path = self.df.iloc[idx]['audio']
spectrograms = generate_cqt_spectrogram(audio_path)
# 选择一个片段进行演示,通常你会基于某种逻辑选择或使用所有片段
spectrogram = spectrograms[0]#只取了第一列的,没有完全采用。 也只需要第一列,后面列全都是0 # 示例中使用第一个片段
eps = 1e-10 # 避免除以零
spectrogram = spectrogram / (np.max(spectrogram) + eps) # 标准化到[0,1]
spectrogram = np.expand_dims(spectrogram, axis=0)
labels = {
'System': torch.tensor(self.df.iloc[idx]['System']),
'Tonic': torch.tensor(self.df.iloc[idx]['Tonic']),
'Pattern': torch.tensor(self.df.iloc[idx]['Pattern']),
}
return torch.from_numpy(spectrogram).float(), labels
def custom_collate_fn(batch):#数据批处理
spectrograms, labels_batch = zip(*batch)
spectrograms_padded = pad_sequence(spectrograms, batch_first=True, padding_value=0)
labels = {task: torch.tensor([label[task] for label in labels_batch]) for task in labels_batch[0]}
return spectrograms_padded, labels
class BasicBlock(nn.Module):#构建残差块
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)# 卷积层
self.bn1 = nn.BatchNorm2d(planes)# 批归一化
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)# 卷积层
self.bn2 = nn.BatchNorm2d(planes)# 批归一化
self.shortcut = nn.Sequential()
# 初始化shortcut连接,如果条件满足则在后面修改此结构
if stride != 1 or in_planes != self.expansion * planes:
# 检查是否需要调整shortcut路径的维度或步长
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
# 如果需要,通过1x1卷积调整维度并匹配主路径的步长。
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x))) # 卷积层
out = self.bn2(self.conv2(out)) # 归一化层
out += self.shortcut(x)
out = F.relu(out)
return out
class MultiTaskResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes_dict):
super(MultiTaskResNet, self).__init__()
self.in_planes = 64# 修改输入层通道数为1,移除降采样
self.conv1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=7, stride=1, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
#num_blocks = [2, 2, 2, 2],残差块2个一层,一共4层,8个残差块。
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 为每个任务添加全连接层,多任务左图的Linear、ReLu、Linear、SoftMax部分
self.system_fc = nn.Linear(512 * block.expansion, num_classes_dict['System'])#num_classes_dict['System'] = 12
self.tonic_fc = nn.Linear(512 * block.expansion, num_classes_dict['Tonic'])#num_classes_dict['Tonic'] = 12
self.pattern_fc = nn.Linear(512 * block.expansion, num_classes_dict['Pattern'])#num_classes_dict['Pattern'] = 5
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
# 任务特定的预测
system_pred = self.system_fc(x)
tonic_pred = self.tonic_fc(x)
pattern_pred = self.pattern_fc(x)
return {'System': system_pred, 'Tonic': tonic_pred, 'Pattern': pattern_pred}
def initialize_model(df, device, learning_rate=0.001):
# 标签值不是从0开始的,可以通过减去最小值来调整它们
df['System'] = df['System'] - df['System'].min()
df['Tonic'] = df['Tonic'] - df['Tonic'].min()
df['Pattern'] = df['Pattern'] - df['Pattern'].min()
#为了实现多任务而定义的字典,方便训练不同任务的时候调取不同的参数
num_classes_dict = {
'System': 12,
'Tonic': 12,
'Pattern': 5,
}
num_blocks = [2, 2, 2, 2]
# num_blocks = [2, 2, 2, 2],残差块2个一层,一共4层,8个残差块。
model = MultiTaskResNet(BasicBlock, num_blocks, num_classes_dict).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
return model, criterion, optimizer
# 训练模型的函数需要对每个任务计算损失,并将这些损失合并来更新模型
def train_model(train_loader, model, criterion, optimizer, device):
model.train()
total_loss = 0
for inputs, labels in train_loader:
inputs = inputs.to(device)
outputs = model(inputs)
loss = sum(criterion(outputs[task], labels[task].to(device)) for task in labels)
#交叉熵损失函数
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f"Average Loss: {avg_loss:.4f}")
def evaluate_model(val_loader, model, device):
model.eval()
correct = {task: 0 for task in ['System', 'Tonic', 'Pattern']}
total = {task: 0 for task in ['System', 'Tonic', 'Pattern']}
with torch.no_grad():
for inputs, labels in val_loader:
inputs = inputs.to(device)
outputs = model(inputs)
for task, preds in outputs.items():
_, predicted = torch.max(preds, 1)
correct[task] += (predicted == labels[task].to(device)).sum().item()
total[task] += labels[task].size(0)
accuracies = {task: correct[task] / total[task] for task in total}
return accuracies
# 从这里开始处理数据
file_path = './label.csv'
df = pd.read_csv(file_path, encoding='gbk')
audio_dir = os.path.dirname(file_path)
df = df[['File_Name', 'System', 'Tonic', 'Pattern']]
df['audio'] = df['File_Name'].apply(lambda x: os.path.join(audio_dir, 'CNPM_audio', x))
df = df[['audio', 'System', 'Tonic', 'Pattern']]
# 转换过程
transform = transforms.Compose([transforms.ToTensor()])
#由路径到.wav文件,顺带分割训练集和验证集
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
train_dataset = AudioDataset(train_df)
val_dataset = AudioDataset(val_df)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=custom_collate_fn)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, collate_fn=custom_collate_fn)
# 设备选择
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model, criterion, optimizer = initialize_model(df, device, learning_rate=0.001)
# 训练和评估模型
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_model(train_loader, model, criterion, optimizer, device)
accuracies = evaluate_model(val_loader, model, device)
# 修改输出的精确值
ACC1 = accuracies['System']
ACC2 = accuracies['Tonic']
ACC3 = accuracies['Pattern']
ACC4 = (accuracies['Tonic'] + accuracies['Pattern']) / 2
print(f"ACC1(System Accuracy): {ACC1:.4f}")
print(f"ACC2(Tonic Accuracy): {ACC2:.4f}")
print(f"ACC3(Pattern Accuracy): {ACC3:.4f}")
print(f"ACC4(Average Tonic and Pattern Accuracy): {ACC4:.4f}")
print("Done!")